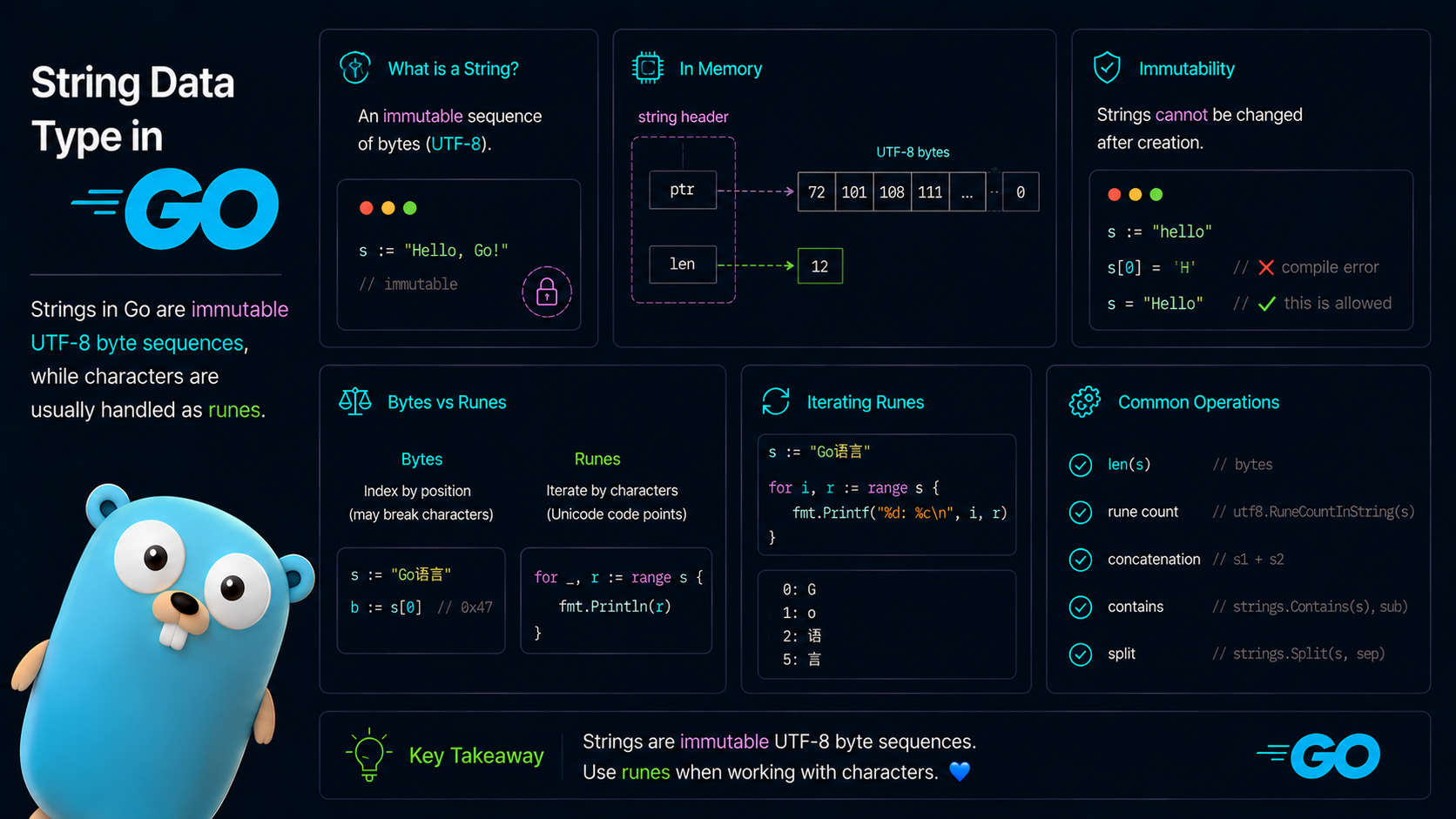
Strings in Go are written with double quotes, not single quotes.
message := "Hello World"That looks simple, but strings in Go are worth understanding carefully. A Go string is an immutable sequence of bytes. By convention, those bytes usually contain UTF-8 encoded text.
That means we need to separate two ideas:
- Bytes are the raw data stored in the string.
- Runes are Unicode code points, which are closer to what we usually mean by “characters”.
Let’s walk through both.
Declaring A String
To declare an empty string variable, use the string type.
package main
import "fmt"
func main() {
var s string
fmt.Printf("value: %q\n", s)
fmt.Printf("type: %T\n", s)
}Output:
value: ""
type: stringThe zero value of a string is an empty string.
String Length
To find the length of a string, use the built-in len function.
package main
import "fmt"
func main() {
s := "Hello World"
fmt.Println(len(s))
}Output:
11For this string, len(s) returns 11 because every character is an ASCII character, and each ASCII character takes exactly one byte in UTF-8.
That detail matters. len returns the number of bytes, not the number of human-visible characters.
Indexing A String Reads Bytes
When we index a string, Go gives us a byte.
package main
import "fmt"
func main() {
s := "Hello World"
for i := 0; i < len(s); i++ {
fmt.Println(s[i])
}
}Output:
72
101
108
108
111
32
87
111
114
108
100These numbers are the byte values for the characters in "Hello World". For example, 72 is H, 101 is e, and 32 is the space character.
If we want to print the character represented by each byte, we can use %c.
package main
import "fmt"
func main() {
s := "Hello World"
for i := 0; i < len(s); i++ {
fmt.Printf("index=%d value=%v char=%c type=%T\n", i, s[i], s[i], s[i])
}
}Output:
index=0 value=72 char=H type=uint8
index=1 value=101 char=e type=uint8
index=2 value=108 char=l type=uint8
index=3 value=108 char=l type=uint8
index=4 value=111 char=o type=uint8
index=5 value=32 char= type=uint8
index=6 value=87 char=W type=uint8
index=7 value=111 char=o type=uint8
index=8 value=114 char=r type=uint8
index=9 value=108 char=l type=uint8
index=10 value=100 char=d type=uint8uint8 is also known as byte in Go.
Non-ASCII Characters
Now let’s replace o in Hello with õ.
package main
import "fmt"
func main() {
s := "Hellõ World"
fmt.Println("bytes:", len(s))
for i := 0; i < len(s); i++ {
fmt.Printf("index=%d hex=%x char=%c\n", i, s[i], s[i])
}
}Output:
bytes: 12
index=0 hex=48 char=H
index=1 hex=65 char=e
index=2 hex=6c char=l
index=3 hex=6c char=l
index=4 hex=c3 char=Ã
index=5 hex=b5 char=µ
index=6 hex=20 char=
index=7 hex=57 char=W
index=8 hex=6f char=o
index=9 hex=72 char=r
index=10 hex=6c char=l
index=11 hex=64 char=dThe string looks like it has 11 characters, but len(s) returns 12. That is because õ takes two bytes in UTF-8: c3 b5.
When we index the string, we read those bytes separately. That is why %c prints à and µ instead of õ.
Converting A String To Runes
To work with Unicode code points, convert the string to []rune.
package main
import "fmt"
func main() {
s := "Hellõ World"
runes := []rune(s)
fmt.Println("runes:", len(runes))
for i := 0; i < len(runes); i++ {
fmt.Printf("index=%d hex=%x decimal=%d char=%c type=%T\n", i, runes[i], runes[i], runes[i], runes[i])
}
}Output:
runes: 11
index=0 hex=48 decimal=72 char=H type=int32
index=1 hex=65 decimal=101 char=e type=int32
index=2 hex=6c decimal=108 char=l type=int32
index=3 hex=6c decimal=108 char=l type=int32
index=4 hex=f5 decimal=245 char=õ type=int32
index=5 hex=20 decimal=32 char= type=int32
index=6 hex=57 decimal=87 char=W type=int32
index=7 hex=6f decimal=111 char=o type=int32
index=8 hex=72 decimal=114 char=r type=int32
index=9 hex=6c decimal=108 char=l type=int32
index=10 hex=64 decimal=100 char=d type=int32Now õ is treated as one value. Its Unicode code point is U+00F5, which is f5 in hexadecimal and 245 in decimal.
In Go, rune is an alias for int32.
Using range On A String
The range form of a for loop decodes the string as UTF-8 and gives us runes.
package main
import "fmt"
func main() {
s := "Hellõ World"
for index, r := range s {
fmt.Printf("byteIndex=%d rune=%c hex=%x type=%T\n", index, r, r, r)
}
}Output:
byteIndex=0 rune=H hex=48 type=int32
byteIndex=1 rune=e hex=65 type=int32
byteIndex=2 rune=l hex=6c type=int32
byteIndex=3 rune=l hex=6c type=int32
byteIndex=4 rune=õ hex=f5 type=int32
byteIndex=6 rune= hex=20 type=int32
byteIndex=7 rune=W hex=57 type=int32
byteIndex=8 rune=o hex=6f type=int32
byteIndex=9 rune=r hex=72 type=int32
byteIndex=10 rune=l hex=6c type=int32
byteIndex=11 rune=d hex=64 type=int32Notice that index 5 is missing. That byte is the second byte of õ, so it is not the start of a new rune.
If you do not need the byte index, use the blank identifier.
for _, r := range s {
fmt.Printf("%c\n", r)
}What Is A Rune?
A rune is a Unicode code point. In Go, we can write a rune literal with single quotes.
package main
import "fmt"
func main() {
r := 'õ'
fmt.Printf("hex=%x decimal=%d type=%T\n", r, r, r)
}Output:
hex=f5 decimal=245 type=int32This is why single quotes are not used for strings in Go. They represent rune literals.
Strings Are Immutable
Strings are immutable. You cannot assign to a string index.
package main
func main() {
s := "Hello"
s[0] = 'M'
}The program does not compile.
cannot assign to s[0]If you need to modify text, convert it to bytes or runes first, then build a new string.
package main
import "fmt"
func main() {
b := []byte("Hello")
b[0] = 'M'
fmt.Println(string(b))
}Output:
MelloYou can also create a string from a byte slice directly.
bytes := []uint8{72, 101, 108, 108, 111}
text := string(bytes)
fmt.Println(text) // HelloRemember:
byteis an alias foruint8.runeis an alias forint32.
Raw String Literals
Go also supports raw string literals with backticks.
package main
import "fmt"
func main() {
s := `Hello
"World"
\n is not treated as a newline here`
fmt.Println(s)
}Output:
Hello
"World"
\n is not treated as a newline hereInside a raw string literal, backslashes have no special meaning. Newlines are preserved, and double quotes do not need to be escaped.
Character Comparison
Rune values can be compared because they are integer code points.
package main
import "fmt"
func main() {
fmt.Println('b' > 'a')
fmt.Println('A' < 'a')
}Output:
true
trueWe can also print the code point values.
package main
import "fmt"
func main() {
fmt.Printf("'a' = %d\n", 'a')
fmt.Printf("'b' = %d\n", 'b')
fmt.Printf("'A' = %d\n", 'A')
}Output:
'a' = 97
'b' = 98
'A' = 65Because runes are numbers, we can loop across a rune range.
package main
import "fmt"
func main() {
for r := 'a'; r <= 'z'; r++ {
fmt.Printf("%c ", r)
}
}Output:
a b c d e f g h i j k l m n o p q r s t u v w x y zStrings in Go are simple once the model clicks: indexing reads bytes, range reads runes, and any modification creates a new string. The strings package gives us common utilities such as search, replace, split, join, trim, and comparison.