What is concurrency?
Concurrency is the ability to deal with multiple things at once.
Think about a browser. You might be downloading a file, listening to music, scrolling a page, and loading images at the same time. If the browser had to finish one task before starting the next one, the experience would be painful.
A single CPU core can still execute only one thing at a time. Concurrency works by splitting CPU time across many tasks quickly enough that they feel active together.
Let’s look at how a CPU can manage browser work like the example we just discussed.
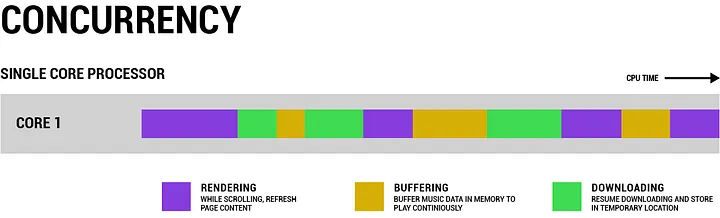
In this diagram, the single core keeps switching between tasks based on priority. That is why your browser can keep scrolling even when another task is waiting on the network.
What is parallelism?
But what happens when the CPU has multiple cores?
A multi-core processor can run different tasks at the same time on different cores. This is parallelism.
In the browser example, a single-core CPU has to share time. A multi-core CPU can run some of those tasks truly side by side.
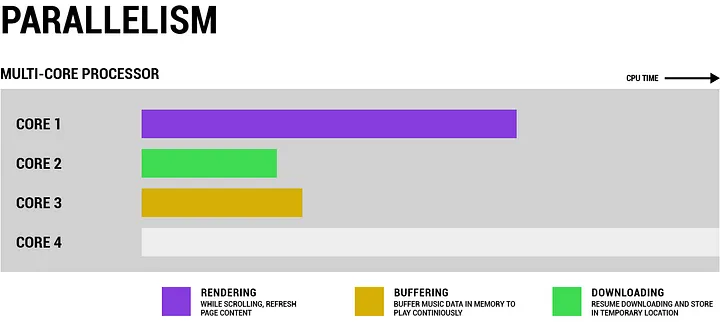
Parallelism can make work faster, but only when the work can actually be split across cores. If tasks spend most of their time waiting on each other, more cores do not automatically solve the problem.
Concurrency vs Parallelism
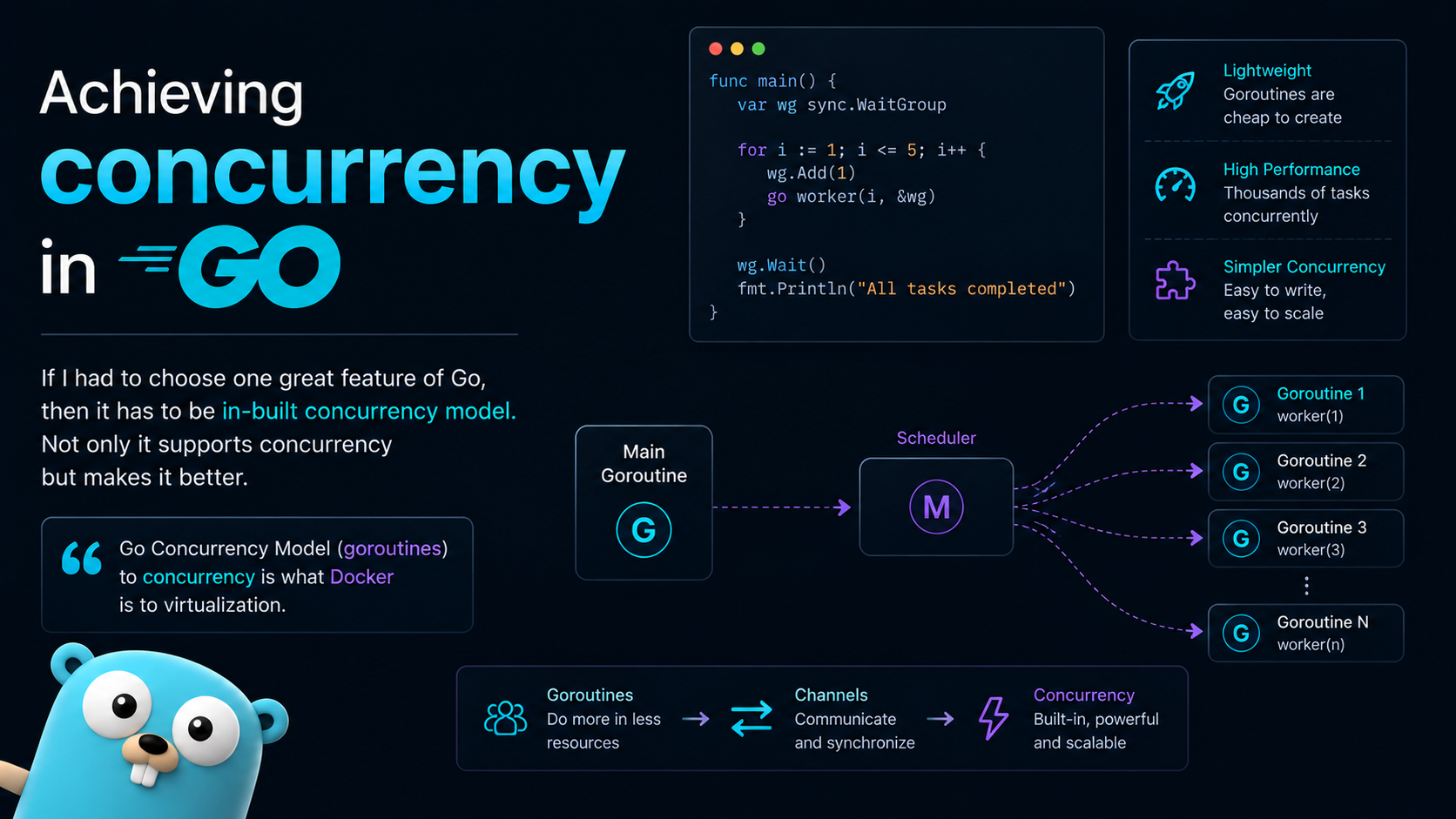
For now, think of goroutines as functions that Go can schedule independently. They are not exactly threads, but they help us write concurrent programs without manually managing OS threads.
The short version is this: concurrency is about dealing with multiple things at once, while parallelism is about doing multiple things at once.
To understand how Go implements concurrency, we first need to talk about processes and threads.
What is a computer process?
When you write a program in languages like C, Java, or Go, the source code starts as text. Your computer cannot execute that text directly, so the code must be compiled into machine instructions. Scripting languages like Python and JavaScript use an interpreter or runtime to handle this process differently.
When the operating system starts a compiled program, it creates a process. A process gets memory, a process ID, a program counter, and other resources. A process has at least one thread, and that thread can create more threads.
In short, a process is a running program with its own memory and OS-managed resources. Threads are the workers inside that process.
What is a thread?
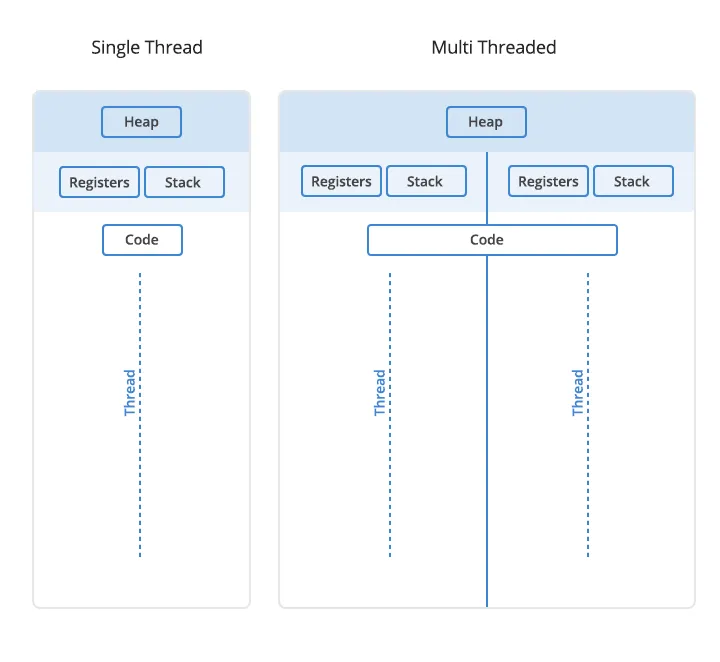
A thread is the unit that actually executes code inside a process. It can access memory and resources owned by that process.
While executing code, a thread stores temporary data on its stack. The stack is usually fixed in size and belongs to that thread. The heap belongs to the process and can be accessed by multiple threads, which is useful but also risky when those threads modify the same data.
Now let’s connect this back to the browser example.
When you open a browser, the OS starts a process. That process may create more processes for tabs and internal services. Each process may also use multiple threads for work like rendering, scrolling, downloading, and playing audio.
Below is the screen-grab of Chrome Browser application on macOS platform.
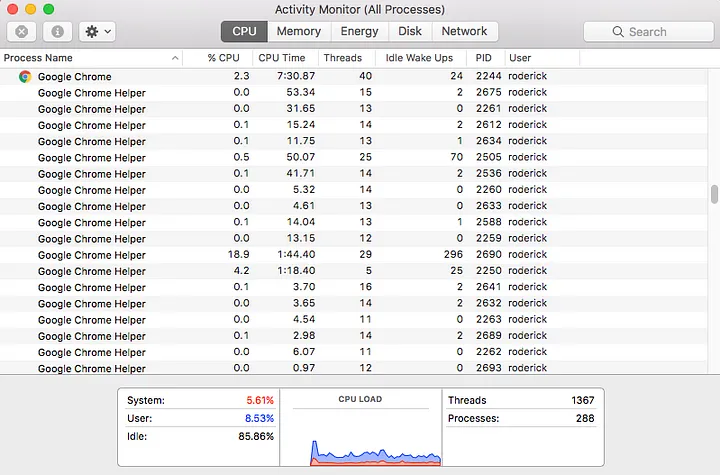
This screen grab shows Chrome using different processes for tabs and internal services. Since each process has at least one thread, a browser can easily end up with many active threads.
The “things” we talked about earlier are usually activities performed by threads. When several of these activities run together, we call that multi-threading.
In multi-threading, one badly behaving thread can affect the whole process. If it leaks memory or blocks shared resources, the application can become unresponsive.
Thread scheduling
When multiple threads run together, they need coordination, especially when they share data. The order in which threads get CPU time is called scheduling. OS threads are scheduled by the kernel, while some runtimes also manage their own scheduling on top of OS threads.
When multiple threads or goroutines access the same data at the same time, and at least one of them writes to it, we can get a race condition. We will come back to this when we talk about channels and synchronization.
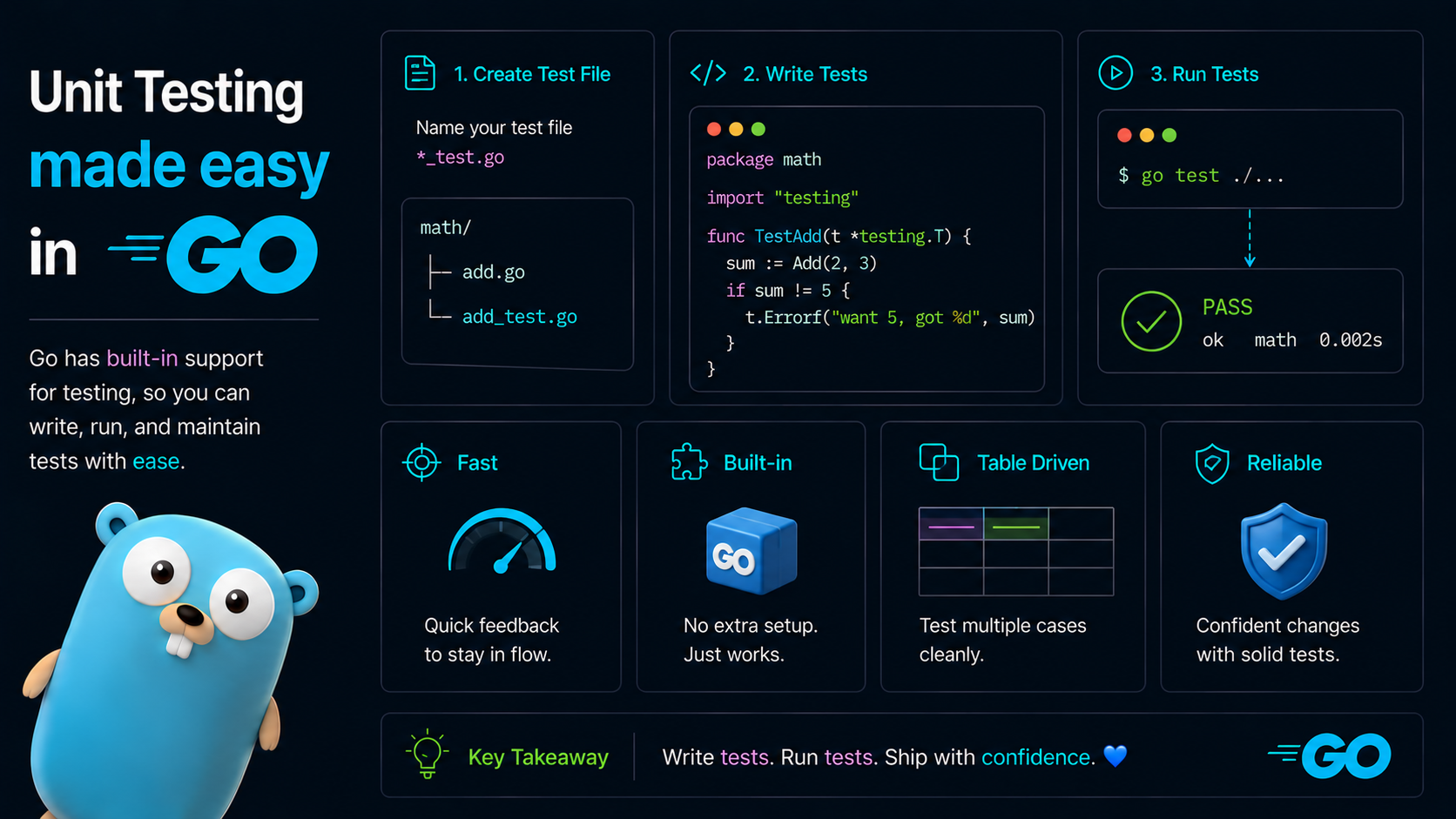
Concurrency in Go
Now we can talk about Go.
Traditional languages often expose threads directly. Go gives us the go keyword to create goroutines. When we put go before a function call, Go runs that function concurrently.
Goroutines feel like lightweight threads, but technically they are scheduled by the Go runtime over a smaller number of OS threads. If one goroutine blocks, the runtime can schedule another goroutine on an available thread.
Go can use multiple CPU cores. The GOMAXPROCS setting controls how many OS threads can execute Go code at the same time. More cores can help CPU-heavy work, but they are not magic. If a program spends most of its time coordinating over channels, adding more parallelism can sometimes make it slower.
Go has an M:N scheduler that can also utilize multiple processors. At any time, M goroutines need to be scheduled on N OS threads that run on at most on GOMAXPROCS numbers of processors. At any time, at most only one thread is allowed to run per core. But scheduler can create more threads if required, but that rarely happens. If your program doesn’t start any additional goroutines, it will naturally run in only one thread no matter how many cores you allow it to use.
Threads vs Goroutines
Since there is an obvious difference between threads and goroutines as we have seen earlier but below differences will shed some light on why threads are more expensive than goroutines and why goroutines is a key solution for achieving the highest level of concurrency in your application.
| Thread | Goroutine |
|---|---|
| OS threads are managed by the kernel and have hardware dependencies. | Goroutines are managed by the Go runtime and have no direct hardware dependency. |
| OS threads generally have a fixed stack size of 1-2MB. | Goroutines start with a much smaller stack that can grow and shrink at runtime. |
| Thread stack size is usually determined ahead of time. | Goroutine stack size is managed by the Go runtime. |
| Threads do not have a simple built-in communication mechanism. Inter-thread communication can be expensive. | Goroutines commonly communicate through channels with low overhead. |
| Threads have identity, such as a thread ID. | Goroutines intentionally do not expose an identity. |
| Creating and destroying OS threads has noticeable setup and teardown cost. | Goroutines are cheap to create and destroy because the Go runtime multiplexes them over OS threads. |
| Threads are preemptively scheduled by the OS. Context switching can be expensive. | Goroutines are scheduled by the Go runtime, and switching between them is usually cheaper. |
These differences matter in real applications. Imagine a web server handling many requests. If every request needs its own OS thread, memory usage grows quickly. If each thread reserves even 1MB of stack space, a thousand concurrent requests can become expensive.
Goroutines start with a much smaller stack that can grow when needed. That makes it practical to create many goroutines for I/O-heavy work like servers, background jobs, and workers.
Switching between goroutines is usually cheaper than switching between OS threads. If a goroutine blocks while waiting for I/O, sleep, or a channel operation, the Go runtime can schedule another goroutine in its place.
- network input
- sleeping
- channel operation
- blocking on primitives in the sync package
If a goroutine never blocks and keeps doing CPU work forever, it can starve other goroutines. That is usually a design problem.
Channels give goroutines a structured way to communicate. Instead of many goroutines directly mutating shared memory, we can pass values through channels and reduce the chance of race conditions.
More resources
There is a great article on Go scheduler by the name of Go’s work-stealing scheduler by Jaana Dogan which you should read to know how Go’s runtime manages goroutines.
There is a great talk by Rob Pike on concurrency of GoLang with the title “Concurrency Is Not Parallelism”.
Now that we understand the rough idea, let’s move to goroutines and see how we actually create concurrent work in Go.